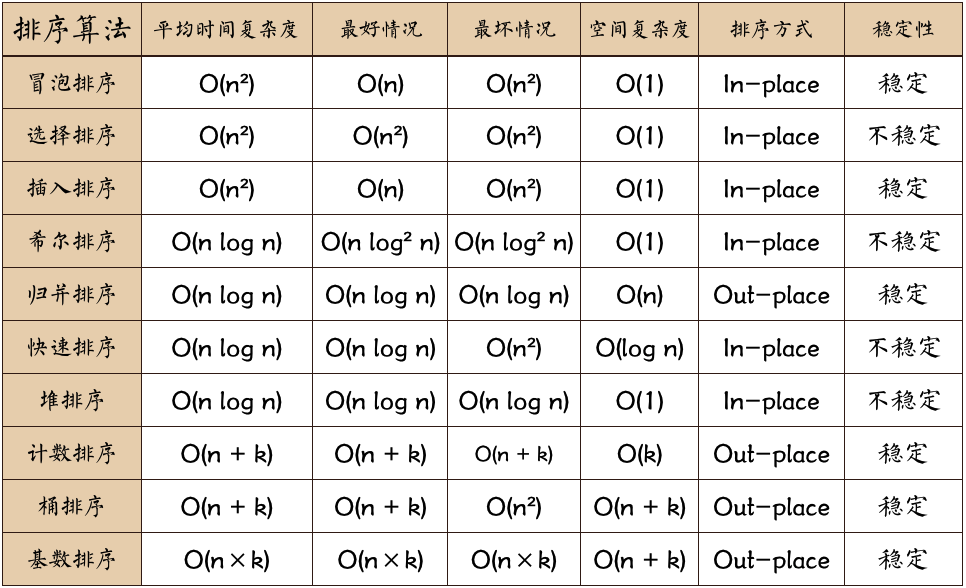
- MySQL 之 Explain 输出分析 https://mp.weixin.qq.com/s/yOZ3WglZMZJaV9H7ruzA6g id 查询语句的标识 select_type 查询的类型 table 当前行所查的表 partitions 匹配的分区 type 访问类型 possible_keys 查询可能用到的索引 key mysql 决定采用的索引来优化查询 key_len 索引 key 的长度 ref 显示了之前的表在key列记录的索引中查找值所用的列或常量 rows 查询扫描的行数,预估值,不一定准确 filtered 查询的表行占表的百分比 extra 额外的查询辅助信息
About
MySQL有四种类型的日志:Error Log、General Query Log、Binary Log 和 Slow Query Log。
第一种错误日志,记录MySQL运行过程ERROR,WARNING,NOTE等信息,系统出错或者某条记录出问题可以查看ERROR日志。
第二种日常运行日志,记录MySQL运行中的每条请求数据。
第三种二进制日志,包含了一些事件,这些事件描述了数据库的改动,如建表、数据改动等,也包括一些潜在改动,主要用于备份恢复、回滚等操作。
第四种慢查询日志,用于MySQL性能调优。
Error Log
MySQL错误日志默认以hostname.err存放在MySQL日志目录,如果不知道MySQL当前的错误日志目录可以使用查询语句:
mysql> show variables like 'log_error';
+---------------+--------------------------------------+
| Variable_name | Value |
+---------------+--------------------------------------+
| log_error | /usr/local/var/mysql/mysql-error.log |
+---------------+--------------------------------------+
修改错误日志地址可以在/etc/my.cnf中添加--log-error[=file_name]选项来开启mysql错误日志。
错误日志记录了MySQL Server每次启动和关闭的详细信息以及运行过程中所有较为严重的警告和错误信息。
知道了MySQL错误日志地址,我们就可以查看MySQL错误日志:
2015-09-12 16:03:20 2624 [ERROR] InnoDB: Unable to lock ./ibdata1, error: 35
2015-09-12 16:03:20 2624 [Note] InnoDB: Check that you do not already have another mysqld process using the same InnoDB data or log files.
2015-09-13 00:03:21 2183 [Note] InnoDB: Shutdown completed; log sequence number 426783897
InnoDB: Unable to lock ./ibdata1, error: 35 可以得出资源被抢占,有可能是开了多个MySQL线程。
General Query Log
日常请求的SQL:
添加方式一样在 /etc/my.cnf 中添加 general-log-file[=file_name]。
查看状态
show global variables like "%genera%";
因为为了性能考虑,一般general log不会开启。 slow log可以定位一些有性能问题的sql,而general log会记录所有的SQL。 mysql5.0版本,如果要开启slow log、general log,需要重启, 从MySQL5.1.6版开始,general query log和slow query log开始支持写到文件或者数据库表两种方式, 并且日志的开启,输出方式的修改,都可以在Global级别动态修改。
root@(none) 09:40:33>
select version();
+————+
| version() |
+————+
| 5.1.37-log |
+————+
1 row in set
(0.02 sec)
输出方式
设置日志输出方式为文件(如果设置log_output=table的话,则日志结果会记录到名为gengera_log的表中,这表的默认引擎都是CSV):
root@(none) 09:41:11>
set global log_output = file;
Query OK, 0 rows affected (0.00 sec)
设置日志文件路径
root@(none) 09:45:06>
set global general_log_file = ’ / tmp / general.log’;
Query OK, 0 rows affected (0.00 sec)
开启general log:
root@(none) 09:45:22>
set global general_log = on;
Query OK, 0 rows affected (0.02 sec)
过一段时间后,关闭general log:
root@(none) 09:45:31>
set global general_log = off;
Query OK, 0 rows affected (0.02 sec)
查看tmp/general.log的信息,可以大致看到哪些sql查询/更新/删除/插入比较频繁了。比如有些表不是经常变化的,查询量又很大,就完全可以cache;对主备延迟要求不高的表,读可以放到备库;等等
Binary Log
启用Binlog
修改 /etc/my.cnf:
binlog_format = STATEMENT
binlog_cache_size = 2M
max_binlog_cache_size = 4M
max_binlog_size = 512M
log-bin = master-bin
log-bin-index = master-bin.index
log-bin-index 指向 master-bin 这个文件,记录有哪些分块的Binlog文件名。
log-bin 记录Binlog文件名前缀,后缀会用数字递增。
Binlog格式
Binlog有3种格式,STATMENT,ROW,MIXED。https://dev.mysql.com/doc/refman/5.1/en/binary-log-mixed.html
混合格式(mixed)会在适当时候切换row和statment格式,statment就是直接的SQL语句格式。
分析Binlog
通过MySQL自带的mysqlbinlog 命令,可以直接查看到Binlog转码数据:
mysqlbinlog /usr/local/var/mysql/master-bin.000117
得到:
at 335
150913 0:05:12 server id 1 end_log_pos 366 CRC32 0xa31b50db Xid = 151
COMMIT/*!*/;
DELIMITER ;
End of log file
ROLLBACK /* added by mysqlbinlog */;
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
第一行包含日志文件偏移字节值(335)。
第二行包含:
事件的日期事件,MySQL会使用他们来产生SET TIMESTAMP
服务器的服务器id
end_log_pos 下一个事件的偏移字节
事件类型,这里是Xid,常见的还有其他,例如:Intvar,Query,Stop,Format_desc
原服务器上执行语句的线程id,用于审计和CONNECTION_ID()
exec_time对于master端的Binlog来说是执行这个event所花费的时间
原服务器产生的错误代码
通过
mysql> show binlog events;
//也可以的到binlog数据:
| master-bin.000002 | 3861 | Query | 1 | 3954 | BEGIN|
| master-bin.000002 | 3954 | Intvar | 1 | 3986 | INSERT_ID=5|
| master-bin.000002 | 3986 | Query | 1 | 4475 | use `dropbox`; INSERT INTO `UserLog` (`uid`, `fids`, `nids`, `msg`, `log`, `from`, `type`, `ctime`) VALUES ('1', '[\"35\",\"33\",\"21\"]', '[\"22\",\"21\",\"11\",\"4\",\"3\"]', '从垃圾箱恢复: 恢复文件 \'[\"35\",\"33\",\"21\"]\' 恢复文件夹 \'[\"22\",\"21\",\"11\",\"4\",\"3\"]\'', '[[\"35\",\"33\",\"21\"],[\"22\",\"21\",\"11\",\"4\",\"3\"]]', 'cloud.jue.so', 'recover_by_trash', '2015-09-07 00:51:31')|
| master-bin.000002 | 4475 | Xid | 1 | 4506 | COMMIT /* xid=423 */
查看Binlog信息
mysql> show variables like '%binlog%';
+-----------------------------------------+----------------------+
| Variable_name | Value |
+-----------------------------------------+----------------------+
| binlog_cache_size | 2097152 |
| binlog_checksum | CRC32 |
| binlog_direct_non_transactional_updates | OFF |
| binlog_error_action | IGNORE_ERROR |
| binlog_format | STATEMENT |
| binlog_gtid_simple_recovery | OFF |
| binlog_max_flush_queue_time | 0 |
| binlog_order_commits | ON |
| binlog_rows_query_log_events | OFF |
| binlog_stmt_cache_size | 32768 |
| binlogging_impossible_mode | IGNORE_ERROR |
| innodb_api_enable_binlog | OFF |
| innodb_locks_unsafe_for_binlog | OFF |
| max_binlog_cache_size | 4194304 |
| max_binlog_size | 536870912 |
| max_binlog_stmt_cache_size | 18446744073709547520 |
| simplified_binlog_gtid_recovery | OFF |
+-----------------------------------------+----------------------+
Slow Query Log
开启 Slow Query
修改/etc/my.cnf:
slow-query-log = 1
slow-query-log-file = /usr/loval/var/mysql/mysql-slow.log
long_query_time = 1 #设置满请求时间
log-queries-not-using-indexes
Slow Query工具
Slow Query有很多查看工具,比如:MySQL自带的mysqldumpslow 和 mysqlsla,用的比较多的 py-query-digest,还可以将满请求数据丢给zabbix做显示分析处理。
这里我用 py-query-digest /usr/local/var/mysql/mysql-slow.log 导出了满请求的数据,例如:
# Query 1: 0.02 QPS, 0.55x concurrency, ID 0xFC19E4D04D8E60BF at byte 12547
# This item is included in the report because it matches --limit.
# Scores: V/M = 118.26
# Time range: 2015-09-12 05:52:03 to 05:57:54
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 1 7
# Exec time 78 194s 250ms 169s 28s 167s 57s 992ms
# Lock time 0 901us 111us 158us 128us 152us 18us 119us
# Rows sent 0 5 0 1 0.71 0.99 0.45 0.99
# Rows examine 7 545.01k 14.18k 97.66k 77.86k 97.04k 32.08k 97.04k
# Query size 0 868 123 125 124 124.25 1 118.34
# String:
# Databases mysqltest
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms ################################################################
# 1s ##########################################
# 10s+ ##########################################
# Tables
# SHOW TABLE STATUS FROM `mysqltest` LIKE 'File'\G
# SHOW CREATE TABLE `mysqltest`.`File`\G
# SHOW TABLE STATUS FROM `mysqltest` LIKE 'User'\G
# SHOW CREATE TABLE `mysqltest`.`User`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT count(*)
FROM `File`
LEFT JOIN `User` ON `User`.`name` = `File`.`name`
WHERE `User`.`name` LIKE '%r%'
order by `last`\G
可以看到该SQL被调用7次,平均每次28s,好慢...平均检测数据大小77.86k。
再来看看SQL语句:
SELECT count(*)
FROM File
LEFT JOIN User ON User.name = File.name
WHERE User.name LIKE '%r%'
order by last
看着都觉得慢 ON User.name= File.name 在没有建立索引的情况下,所有数据将进行字符串匹配name字段。
这个库有 15W条User数据,10W条File数据,也就是要比对15*10 WW 次数据。
MySQL的slow log的作用也就在这里了,优化慢查询。
参考:
1.《高性能MySQL》
2.(Analyse slow-query-log using mysqldumpslow & pt-query-digest)[https://rtcamp.com/tutorials/mysql/slow-query-log/]
3.初探:MySQL 的 Binlog&version=11020201&pass_ticket=DNtPK7ePVYl93tx1FiRMBNsJMm3DEgwRdO1XEZUustRXuYf6KyUU4gID1Lv7aVTB)